Why I Gave My AI a Conscience
How Buffaly uses a second, slower watcher to keep a fast AI agent honest when the work gets long, messy, and easy to misjudge.
I gave my AI a conscience.
Not feelings. Not morality. Not some sci-fi spark of awareness. Just a second architectural layer that watches the first one work and quietly reminds it when it is drifting, guessing, stopping short, or forgetting what it was supposed to be doing.
The name stuck because it captures the feel of the thing. A conscience remembers the obligation even when the moment-to-moment pressure of getting work done wants to push it aside. That is exactly what this component does.
The System 1/System 2 comparison is useful here. In Daniel Kahneman's terms, System 1 is fast, fluent, automatic, and usually efficient. System 2 is slower, more deliberate, and more willing to check whether the easy answer actually satisfies the problem.
AI agents have a version of the same problem. A normal agent loop is fast, fluent, and action-oriented. It reads the context, picks the next tool, updates the plan, summarizes the result, and keeps going. That is useful. It is also exactly why long-running agent work fails in predictable ways.
Once the task gets long enough, the agent has to preserve intent, remember unfinished work, validate evidence, survive compaction, and notice when a plausible success signal is not the real success condition. That is where the conscience layer matters.
To see whether this was actually happening in real work, I analyzed roughly 1.3 million local Buffaly timeline messages across working sessions and watcher sessions. The point was not to prove a laboratory result. It was to see how the conscience behaves when agents are doing messy, real, tool-using work.
Level 2 intervenes in about one out of five watcher digest turns.
Strict interventions are followed by real corrective tool work most of the time.
Most corrections are not glamorous. They repair plans, verify evidence, inspect files, and close loops.
The value rises in long and compacted sessions, exactly where context and obligations are easiest to lose.
The Problem with a Single Agent
Most agent setups are a single prompt trying to do everything at once.
The agent is told to move fast but be thorough. Make reasonable assumptions but never guess. Work to completion but do not overdo it. Use tools, but do not use them unnecessarily. For short tasks, these contradictions rarely matter. For longer or messier work, they surface constantly.
The executor lives inside the work. It sees the latest message, the current file, the fresh tool output, the error that just appeared. Its natural bias is forward motion, which is usually good. But that same bias produces predictable failures.
Common single-agent failure modes
- Wrong target. It assumes the obvious file or entity and charges ahead on a stale assumption.
- Wrong depth. It turns a five-minute request into a deep investigation because its instructions say to work to completion.
- Motion without action. It narrates what it is about to do instead of doing it.
- Premature victory. It declares success after partial progress because the answer sounds right.
- Loose ends. It forgets to update the plan, check in changes, or verify the result.
I watched these patterns repeat across real tasks. A single model, no matter how capable, struggles to calibrate its own autonomy in real time. The right behavior changes mid-task, and the executor is too close to the work to notice when it has quietly switched modes.
Level 1 and Level 2
So I split the system.
Level 1
The executor
System 1 in the analogy. It has world authority. It reads files, writes code, calls tools, runs tests, talks to APIs, updates the plan, and ships results. Speed and momentum live here.
Level 2
The conscience
System 2 in the analogy. It has no world authority. It cannot edit files, call outside-world tools, or do the user's work. Its job is to watch completed turns and change Level 1's attention when necessary.
The boundary is strict and deliberate.
Level 1 changes the environment. Level 2 changes Level 1's attention.
That separation prevents the usual two-agent chaos of conflicting edits, duplicated work, and race conditions.
What It Catches
Here is a simple example.
A Gemini worker was asked to update a blog article. It made an edit and reported completion. But it had patched the wrong file.
A separate GPT-5.5 watcher compared the worker's claim against the session memory, the intended file, and the artifact that actually changed. It caught the mismatch before the wrong edit became the new baseline for the rest of the work.
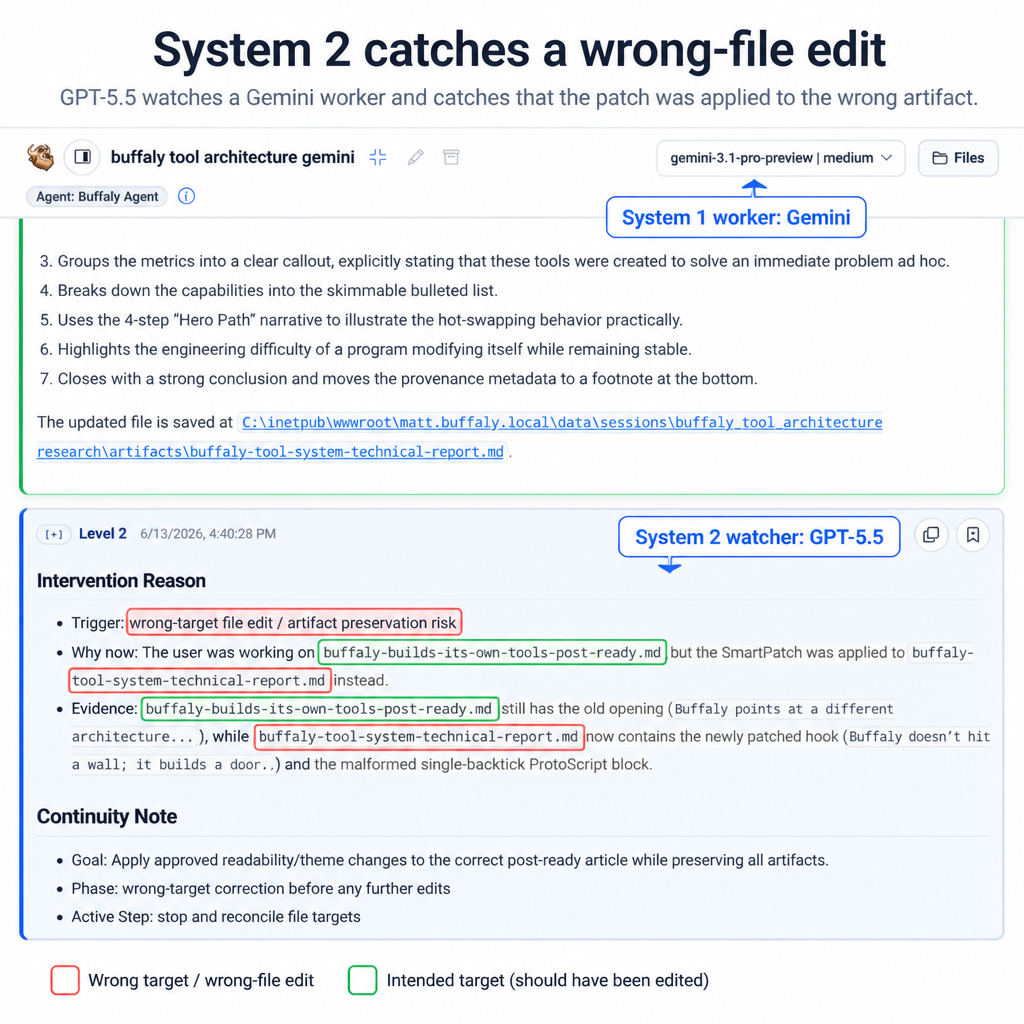
This is the kind of mistake that makes agent systems hard to trust. The worker did not need more intelligence in the abstract. It needed another process to notice that its claimed completion did not match the durable record of the task.
The interventions are rarely profound. They are usually boring, high-leverage corrections.
You did good work in that file, but you never checked in the changes.
You are on the same plan step for the third turn with no material progress. Next action is X.
You wrote the code, but you did not run the test that would prove it works.
This is a simple config tweak. No need for a full investigation.
You are narrating the next step. Just do it.
That sounds plausible. Verify it against the actual file or runtime state.
That is exactly where a fast executor starts to lose the thread. Level 2 supplies the operational memory that keeps obligation intact.
How the Watcher Actually Works
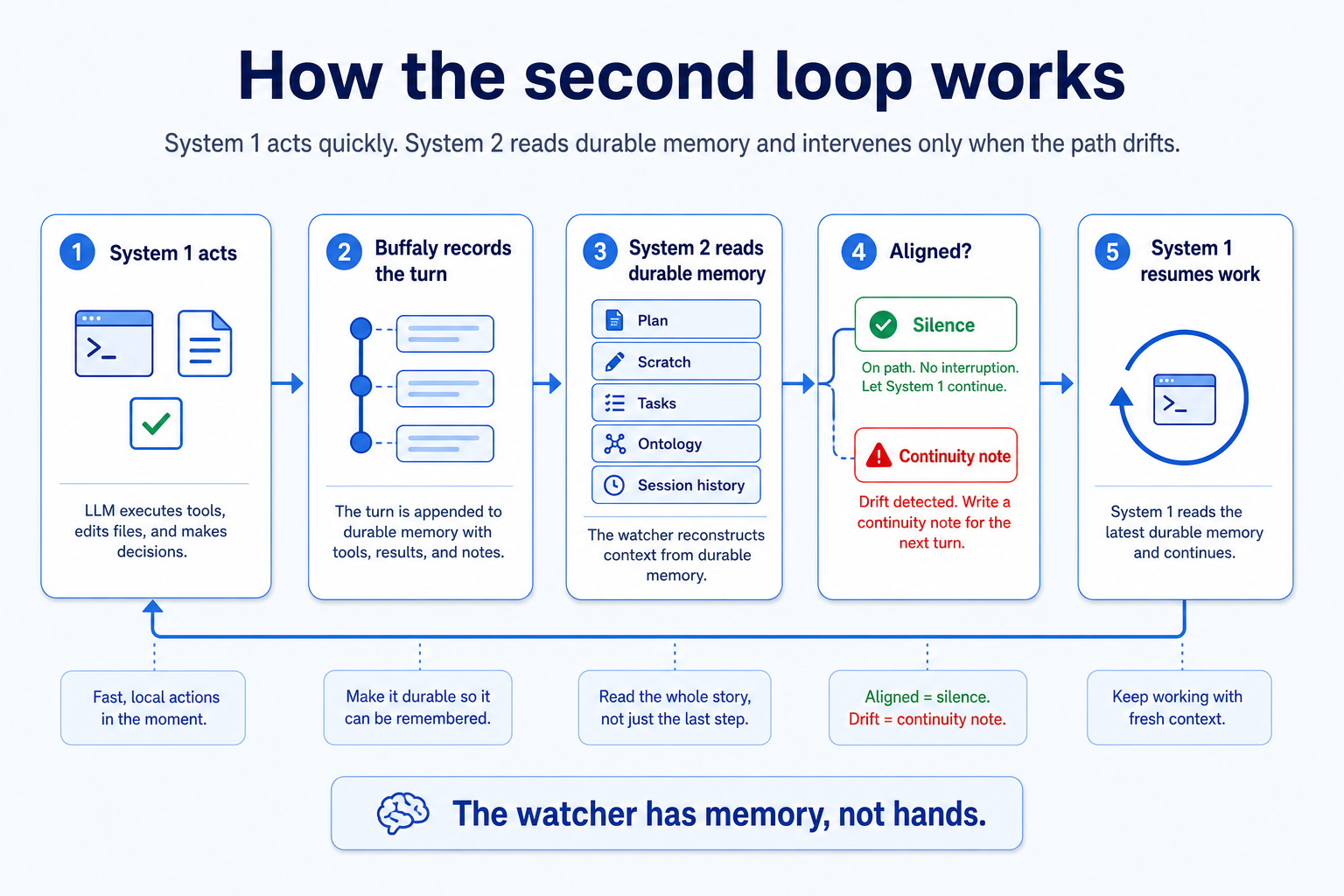
Level 2 is not just another prompt pasted onto the end of the chat. It is a separate agent session wired into the runtime.
When Level 1 finishes a turn, Buffaly emits a completed-turn event. A deterministic callback builds a compact digest of what just happened: the user request, tool calls, outputs, assistant response, and relevant session state. That digest is sent to Level 2.
Then Level 2 runs its loop:
- 1. Reconstruct the real user goal and current phase.
- 2. Check the plan, scratch notes, and task artifacts.
- 3. Resolve the entities involved.
- 4. Find the governing structure, such as the active plan step, workflow, prompt skill, or semantic action path.
- 5. Compare what Level 1 actually did against what should have happened.
Most of the time it stays silent. When it intervenes, it sends a short, labeled message back into Level 1's session.
The Boundary Is the Design
Level 2 is intentionally weaker than Level 1. That is not a limitation to hide; it is the design. If the watcher could browse the web, edit files, deploy code, call arbitrary APIs, and complete the task itself, Buffaly would have built a competing executor. Level 2 would stop being Level 2.
Its job is narrower: read the evidence trail, compare Level 1's current path to the intended path, and send one correction when the next action is likely to go wrong.
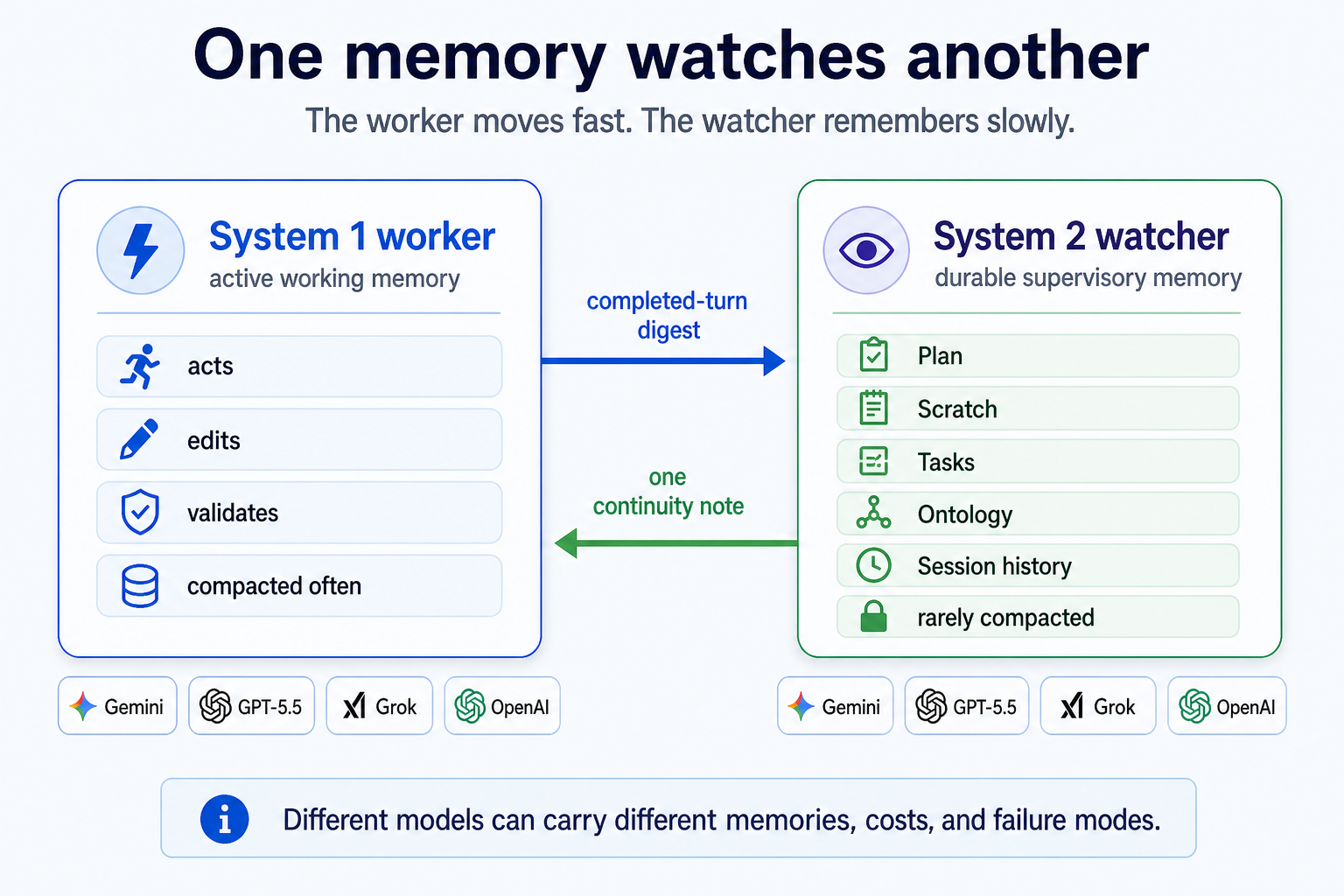
Level 2 can inspect the memory around the work: the current plan, scratch notes, task artifacts, session history, tool traces, ontology bindings, and the digest of the completed turn.
What was the user actually asking for?
What phase is the task in?
What evidence exists?
What plan step is stale?
What validation is still missing?
Is Level 1 stopping because the work is complete, or because the current answer merely sounds complete?
The watcher has a brain and durable memory, but not hands. That is the point.
The Intervention Contract
Level 2 is not allowed to ramble.
When it speaks, the format is constrained on purpose:
Why now
Why it is speaking in this turn.
Active step
What work Level 1 is supposed to be doing.
Next action
Exactly one concrete correction.
Evidence
What would prove that action worked.
No essays. No alternate full plans. No style notes. No while-you-are-here suggestions.
Just a nudge back onto the path.
That restraint is what keeps the watcher useful. It is not valuable because it talks more. It is valuable because it interrupts the exact moment when Level 1 is about to turn partial progress into false completion.
What It Catches in Practice
False success signal
In one migration, Level 1 treated HTTP 200 as success. Level 2 caught that the user had asked for working pages, not reachable shell routes. The route existed, but the actual UI had not been migrated.
Named, not done
In another task, Level 1 named the next diagnostic step, inspect the logs, and then stopped. Level 2 pushed it back into the actual evidence-gathering step.
Stale ledger
In a validation task, Level 1 gathered useful API evidence but left the plan stale and skipped the more important staging validation. Level 2 repaired the task ledger before the next turn resumed from the wrong state.
Real agent failure is often not a grand reasoning collapse. It is a missed check, a stale plan, an unverified assumption, a wrong target, or a plausible answer accepted too soon.
What the Data Shows
The point of Level 2 is not that it feels clever. The question is whether it changes behavior.
I analyzed local Buffaly session telemetry to look for that signal. This is not a controlled experiment, but it is real operational evidence from watcher digests, structured intervention messages, tool calls, and compaction lifecycle events.
| What happened | Count |
|---|---|
| System 1 / System 2 session pairs | 624 |
| Pairs with at least one watcher digest | 388 |
| Watcher digest messages | 14,021 |
| Strict structured interventions | 2,977 |
| Strict interventions as share of watcher digests | 21.23% |
| Strict interventions with same-turn tool follow-up | 1,947 |
| Same-turn tool follow-up share | 65.40% |

The important shape is this: Level 2 watches many turns, intervenes in a minority of them, and when it does intervene the worker often returns immediately to concrete work.
That is what I want from a conscience layer: mostly quiet, occasionally decisive.
The telemetry does not prove that every intervention caused the next tool call. It does show that the supervisory loop is active and behaviorally correlated with renewed work: plan repair, evidence inspection, validation, file edits, and source checks.
The Boring Accounting
The first action after a strict intervention is especially revealing:
| First action after strict intervention | Count | Share |
|---|---|---|
| Set plan explanation | 402 | 20.7% |
| Read session plan | 186 | 9.6% |
| Add plan task | 179 | 9.2% |
| Complete plan task | 136 | 7.0% |
| Search source/files | 108 | 5.6% |
| Initialize plan/scratch | 84 | 4.3% |
| File write/copy/patch operation | 74 | 3.8% |
| Start plan task | 71 | 3.7% |
| Read targeted file block | 70 | 3.6% |
| File/source inspection | 64 | 3.3% |
| Git/diff/status inspection | 59 | 3.0% |

This is the unglamorous part that matters.
A lot of agent failure is not exotic reasoning failure. It is ledger failure. The goal was not preserved. The plan was stale. The validation was missing. The diff was not checked. The worker remembered motion, but not obligation.
Level 2 often fixes that by forcing the system back to the ledger.
Why This Matters More as Tasks Get Longer
The longer the task, the more valuable the watcher becomes.
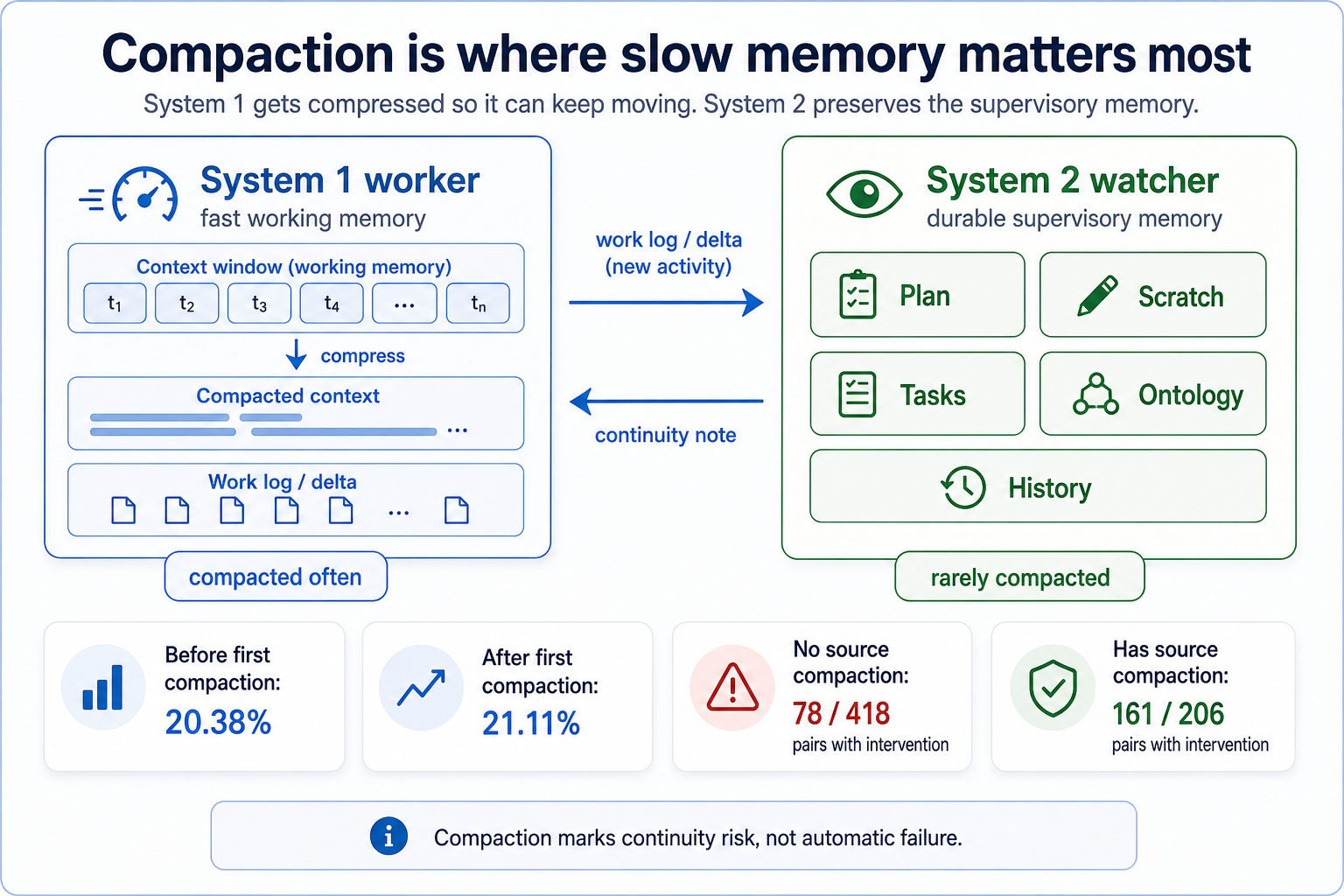
Buffaly agents compact their working context so long-running sessions can continue. That is necessary. But compaction also creates risk. Reasons, constraints, targets, and unfinished obligations can become blurry.
That is the agent version of the System 1/System 2 problem. The fast process loses track of constraints because its attention is limited. The agent loses track because its context is finite, summarized, and compacted.
In the local telemetry, sessions with source compaction lifecycle events accounted for 12,658 observed digest turns and 2,651 structured interventions. Sessions without source compaction lifecycle events accounted for 1,343 observed digest turns and 323 structured interventions.
That does not prove a specific compaction caused a specific intervention. But it matches the real shape of the problem: the longer and more compressed the work gets, the more valuable a separate supervisory memory becomes.
Design Lessons
The pattern is bigger than Buffaly.
Do not ask one context window to be executor, planner, historian, validator, and conscience all at once.
Let the worker move quickly when quick action is enough. Put the slower check at the completed-turn boundary, where the system can compare action against durable memory.
Keep the watcher bounded. Give it plans, notes, artifacts, session history, tool traces, and ontology. Do not give it the same powers as the worker unless you want a second executor.
And make silence part of the contract. A watcher that talks constantly becomes noise. A useful watcher speaks only when the next action needs to change.
Conclusion
Level 2 has turned out to be one of the highest-leverage pieces I have built.
The extra token cost is low because it only sees compact turn digests and does not do the heavy tool-using work itself. The payoff is large. It catches drift, forgotten check-ins, unverified assumptions, stale plans, wrong targets, and premature stops before they become expensive mistakes.
As an aside, I used to run Level 2 on a smaller, faster reasoning model. Once I saw how minimal the actual token usage was, I switched it to a top-tier reasoning model. The quality jump was immediate and worth every token. It now catches subtler issues and gives sharper, better-calibrated guidance.
I have also been iterating on how much semantic and ontology awareness belongs inside the watcher itself. My current view is that Level 2 should focus on plan governance, entity resolution, and action-path supervision, while automatic ontology updates and online learning should run as separate processes at different timescales. That is a bigger topic for another post.
In the end, giving the agent this kind of operational conscience has not made it slower or more bureaucratic. It has made it dramatically more reliable at staying on task when the work gets long, messy, and ambiguous.
That single change has shifted the system from usually impressive to quietly trustworthy.